
Choose any three.
|
Overview
SQLite stores an entire database within a single file, the format of which is described in the SQLite File Database File Format document ff_sqlitert_requirements. Each database file is stored within a file system, presumably provided by the host operating system. Instead of interfacing with the operating system directly, the host application is required to supply an adaptor component that implements the SQLite Virtual File System interface (described in capi_sqlitert_requirements). The adaptor component is responsible for translating the calls made by SQLite to the VFS interface into calls to the file-system interface provided by the operating system. This arrangement is depicted in figure figure_vfs_role.
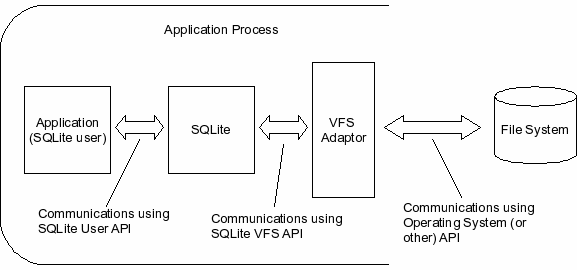
Figure - Virtual File System (VFS) Adaptor
Although it would be easy to design a system that uses the VFS interface to read and update the content of a database file stored within a file-system, there are several complicated issues that need to be addressed by such a system:
SQLite is required to implement atomic and durable transactions (the 'A' and 'D' from the ACID acronym), even if an application, operating system or power failure occurs midway through or shortly after updating a database file.
To implement atomic transactions in the face of potential application, operating system or power failures, database writers write a copy of those portions of the database file that they are going to modify into a second file, the journal file, before writing to the database file. If a failure does occur while modifying the database file, SQLite can reconstruct the original database (before the modifications were attempted) based on the contents of the journal file.
SQLite is required to implement isolated transactions (the 'I' from the ACID acronym).
This is done by using the file locking facilities provided by the VFS adaptor to serialize writers (write transactions) and preventing readers (read transactions) from accessing database files while writers are midway through updating them.
For performance reasons, it is advantageous to minimize the quantity of data read and written to and from the file-system.
As one might expect, the amount of data read from the database file is minimized by caching portions of the database file in main memory. Additionally, multiple updates to the database file that are part of the same write transaction may be cached in main memory and written to the file together, allowing for more efficient IO patterns and eliminating the redundant write operations that could take place if part of the database file is modified more than once within a single write transaction.
System requirement references for the above points.
This document describes in detail the way that SQLite uses the API provided by the VFS adaptor component to solve the problems and implement the strategies enumerated above. It also specifies the assumptions made about the properties of the system that the VFS adaptor provides access to. For example, specific assumptions about the extent of data corruption that may occur if a power failure occurs while a database file is being updated are presented in section fs_characteristics.
This document does not specify the details of the interface that must be implemented by the VFS adaptor component, that is left to capi_sqlitert_requirements.
Relationship to Other Documents
Related to C-API requirements:
- Opening a connection.
- Closing a connection.
Related to SQL requirements:
- Opening a read-only transaction.
- Terminating a read-only transaction.
- Opening a read-write transaction.
- Committing a read-write transaction.
- Rolling back a read-write transaction.
- Opening a statement transaction.
- Committing a statement transaction.
- Rolling back a statement transaction.
- Committing a multi-file transaction.
Related to file-format requirements:
- Pinning (reading) a database page.
- Unpinning a database page.
- Modifying the contents of a database page.
- Appending a new page to the database file.
- Truncating a page from the end of the database file.
Document Structure
Section vfs_assumptions of this document describes the various assumptions made about the system to which the VFS adaptor component provides access. The basic capabilities and functions required from the VFS implementation are presented along with the description of the VFS interface in capi_sqlitert_requirements. Section vfs_assumptions complements this by describing in more detail the assumptions made about VFS implementations on which the algorithms presented in this document depend. Some of these assumptions relate to performance issues, but most concern the expected state of the file-system following a failure that occurs midway through modifying a database file.
Section database_connections introduces the concept of a database connection, a combination of a file-handle and in-memory cache used to access a database file. It also describes the VFS operations required when a new database connection is created (opened), and when one is destroyed (closed).
Section reading_data describes the steps required to open a read transaction and read data from a database file.
Section writing_data describes the steps required to open a write transaction and write data to a database file.
Section rollback describes the way in which aborted write transactions may be rolled back (reverted), either as a result of an explicit user directive or because an application, operating system or power failure occurred while SQLite was midway through updating a database file.
Section page_cache_algorithms describes some of the algorithms used to determine exactly which portions of the database file are cached by a page cache, and the effect that they have on the quantity and nature of the required VFS operations. It may at first seem odd to include the page cache, which is primarily an implementation detail, in this document. However, it is necessary to acknowledge and describe the page cache in order to provide a more complete explanation of the nature and quantity of IO performed by SQLite.
Glossary
After this document is ready, make the vocabulary consistent and then add a glossary here.
VFS Adaptor Related Assumptions
This section documents those assumptions made about the system that the VFS adaptor provides access to. The assumptions noted in section fs_characteristics are particularly important. If these assumptions are not true, then a power or operating system failure may cause SQLite databases to become corrupted.
Performance Related Assumptions
SQLite uses the assumptions in this section to try to speed up reading from and writing to the database file.
It is assumed that writing a series of sequential blocks of data to a file in order is faster than writing the same blocks in an arbitrary order.
System Failure Related Assumptions
In the event of an operating system or power failure, the various combinations of file-system software and storage hardware available provide varying levels of guarantee as to the integrity of the data written to the file system just before or during the failure. The exact combination of IO operations that SQLite is required to perform in order to safely modify a database file depend on the exact characteristics of the target platform.
This section describes the assumptions that SQLite makes about the content of a file-system following a power or system failure. In other words, it describes the extent of file and file-system corruption that such an event may cause.
SQLite queries an implementation for file-system characteristics using the xDeviceCharacteristics() and xSectorSize() methods of the database file file-handle. These two methods are only ever called on file-handles open on database files. They are not called for journal files, master-journal files or temporary database files.
The file-system sector size value determined by calling the xSectorSize() method is a power of 2 value between 512 and 32768, inclusive reference to exactly how this is determined. SQLite assumes that the underlying storage device stores data in blocks of sector-size bytes each, sectors. It is also assumed that each aligned block of sector-size bytes of each file is stored in a single device sector. If the file is not an exact multiple of sector-size bytes in size, then the final device sector is partially empty.
Normally, SQLite assumes that if a power failure occurs while updating any portion of a sector then the contents of the entire device sector is suspect following recovery. After writing to any part of a sector within a file, it is assumed that the modified sector contents are held in a volatile buffer somewhere within the system (main memory, disk cache etc.). SQLite does not assume that the updated data has reached the persistent storage media, until after it has successfully synced the corresponding file by invoking the VFS xSync() method. Syncing a file causes all modifications to the file up until that point to be committed to persistent storage.
Based on the above, SQLite is designed around a model of the file-system whereby any sector of a file written to is considered to be in a transient state until after the file has been successfully synced. Should a power or system failure occur while a sector is in a transient state, it is impossible to predict its contents following recovery. It may be written correctly, not written at all, overwritten with random data, or any combination thereof.
For example, if the sector-size of a given file-system is 2048 bytes, and SQLite opens a file and writes a 1024 byte block of data to offset 3072 of the file, then according to the model the second sector of the file is in the transient state. If a power failure or operating system crash occurs before or during the next call to xSync() on the file handle, then following system recovery SQLite assumes that all file data between byte offsets 2048 and 4095, inclusive, is invalid. It also assumes that since the first sector of the file, containing the data from byte offset 0 to 2047 inclusive, is valid, since it was not in a transient state when the crash occurred.
Assuming that any and all sectors in the transient state may be corrupted following a power or system failure is a very pessimistic approach. Some modern systems provide more sophisticated guarantees than this. SQLite allows the VFS implementation to specify at runtime that the current platform supports zero or more of the following properties:
The safe-append property. If a system supports the safe-append property, it means that when a file is extended the new data is written to the persistent media before the size of the file itself is updated. This guarantees that if a failure occurs after a file has been extended, following recovery the write operations that extended the file will appear to have succeeded or not occurred at all. It is not possible for invalid or garbage data to appear in the extended region of the file.
The atomic-write property. A system that supports this property also specifies the size or sizes of the blocks that it is capable of writing. Valid sizes are powers of two greater than 512. If a write operation modifies a block of n bytes, where n is one of the block sizes for which atomic-write is supported, then it is impossible for an aligned write of n bytes to cause data corruption. If a failure occurs after such a write operation and before the applicable file handle is synced, then following recovery it will appear as if the write operation succeeded or did not take place at all. It is not possible that only part of the data specified by the write operation was written to persistent media, nor is it possible for any content of the sectors spanned by the write operation to be replaced with garbage data, as it is normally assumed to be.
The sequential-write property. A system that supports the sequential-write property guarantees that the various write operations on files within the same file-system are written to the persistent media in the same order that they are performed by the application and that each operation is concluded before the next is begun. If a system supports the sequential-write property, then the model used to determine the possible states of the file-system following a failure is different.
If a system supports sequential-write it is assumed that syncing any file within the file system flushes all write operations on all files (not just the synced file) to the persistent media. If a failure does occur, it is not known whether or not any of the write operations performed by SQLite since the last time a file was synced. SQLite is able to assume that if the write operations of unknown status are arranged in the order that they occurred:
- the first n operations will have been executed successfully,
- the next operation puts all device sectors that it modifies into the transient state, so that following recovery each sector may be partially written, completely written, not written at all or populated with garbage data,
- the remaining operations will not have had any effect on the contents of the file-system.
Failure Related Assumption Details
This section describes how the assumptions presented in the parent section apply to the individual API functions and operations provided by the VFS to SQLite for the purposes of modifying the contents of the file-system.
SQLite manipulates the contents of the file-system using a combination of the following four types of operation:
- Create file operations. SQLite may create new files within the file-system by invoking the xOpen() method of the sqlite3_io_methods object.
- Delete file operations. SQLite may remove files from the file system by calling the xDelete() method of the sqlite3_io_methods object.
- Truncate file operations. SQLite may truncate existing files by invoking the xTruncate() method of the sqlite3_file object.
- Write file operations. SQLite may modify the contents and increase the size of a file by files by invoking the xWrite() method of the sqlite3_file object.
Additionally, all VFS implementations are required to provide the sync file operation, accessed via the xSync() method of the sqlite3_file object, used to flush create, write and truncate operations on a file to the persistent storage medium.
The formalized assumptions in this section refer to system failure events. In this context, this should be interpreted as any failure that causes the system to stop operating. For example a power failure or operating system crash.
SQLite does not assume that a create file operation has actually modified the file-system records within persistent storage until after the file has been successfully synced.
If a system failure occurs during or after a "create file" operation, but before the created file has been synced, then SQLite assumes that it is possible that the created file may not exist following system recovery.
Of course, it is also possible that it does exist following system recovery.
If a "create file" operation is executed by SQLite, and then the created file synced, then SQLite assumes that the file-system modifications corresponding to the "create file" operation have been committed to persistent media. It is assumed that if a system failure occurs any time after the file has been successfully synced, then the file is guaranteed to appear in the file-system following system recovery.
A delete file operation (invoked by a call to the VFS xDelete() method) is assumed to be an atomic and durable operation.
If a system failure occurs at any time after a "delete file" operation (call to the VFS xDelete() method) returns successfully, it is assumed that the file-system will not contain the deleted file following system recovery.
If a system failure occurs during a "delete file" operation, it is assumed that following system recovery the file-system will either contain the file being deleted in the state it was in before the operation was attempted, or not contain the file at all. It is assumed that it is not possible for the file to have become corrupted purely as a result of a failure occurring during a "delete file" operation.
The effects of a truncate file operation are not assumed to be made persistent until after the corresponding file has been synced.
If a system failure occurs during or after a "truncate file" operation, but before the truncated file has been synced, then SQLite assumes that the size of the truncated file is either as large or larger than the size that it was to be truncated to.
If a system failure occurs during or after a "truncate file" operation, but before the truncated file has been synced, then it is assumed that the contents of the file up to the size that the file was to be truncated to are not corrupted.
The above two assumptions may be interpreted to mean that if a system failure occurs after file truncation but before the truncated file is synced, the contents of the file following the point at which it was to be truncated may not be trusted. They may contain the original file data, or may contain garbage.
If a "truncate file" operation is executed by SQLite, and then the truncated file synced, then SQLite assumes that the file-system modifications corresponding to the "truncate file" operation have been committed to persistent media. It is assumed that if a system failure occurs any time after the file has been successfully synced, then the effects of the file truncation are guaranteed to appear in the file system following recovery.
A write file operation modifies the contents of an existing file within the file-system. It may also increase the size of the file. The effects of a write file operation are not assumed to be made persistent until after the corresponding file has been synced.
If a system failure occurs during or after a "write file" operation, but before the corresponding file has been synced, then it is assumed that the content of all sectors spanned by the write file operation are untrustworthy following system recovery. This includes regions of the sectors that were not actually modified by the write file operation.
If a system failure occurs on a system that supports the atomic-write property for blocks of size N bytes following an aligned write of N bytes to a file but before the file has been successfully synced, then is assumed following recovery that all sectors spanned by the write operation were correctly updated, or that none of the sectors were modified at all.
If a system failure occurs on a system that supports the safe-append following a write operation that appends data to the end of the file without modifying any of the existing file content but before the file has been successfully synced, then is assumed following recovery that either the data was correctly appended to the file, or that the file size remains unchanged. It is assumed that it is impossible that the file be extended but populated with incorrect data.
Following a system recovery, if a device sector is deemed to be untrustworthy as defined by A21008 and neither A21011 or A21012 apply to the range of bytes written, then no assumption can be made about the content of the sector following recovery. It is assumed that it is possible for such a sector to be written correctly, not written at all, populated with garbage data or any combination thereof.
If a system failure occurs during or after a "write file" operation that causes the file to grow, but before the corresponding file has been synced, then it is assumed that the size of the file following recovery is as large or larger than it was when it was most recently synced.
If a system supports the sequential-write property, then further assumptions may be made with respect to the state of the file-system following recovery from a system failure. Specifically, it is assumed that create, truncate, delete and write file operations are applied to the persistent representation in the same order as they are performed by SQLite. Furthermore, it is assumed that the file-system waits until one operation is safely written to the persistent media before the next is attempted, just as if the relevant file were synced following each operation.
If a system failure occurs on a system that supports the sequential-write property, then it is assumed that all operations completed before the last time any file was synced have been successfully committed to persistent media.
If a system failure occurs on a system that supports the sequential-write property, then it is assumed that the set of possible states that the file-system may be in following recovery is the same as if each of the write operations performed since the most recent time a file was synced was itself followed by a sync file operation, and that the system failure may have occurred during any of the write or sync file operations.
Database Connections
Within this document, the term database connection has a slightly
different meaning from that which one might assume. The handles returned
by the sqlite3_open() and sqlite3_open16()
APIs (reference) are referred to as database
handles. A database connection is a connection to a single
database file using a single file-handle, which is held open for the
lifetime of the connection. Using the SQL ATTACH syntax, multiple
database connections may be accessed via a single database
handle. Or, using SQLite's shared-cache mode feature, multiple
database handles may access a single database connection.
Usually, a new database connection is opened whenever the user opens new database handle on a real database file (not an in-memory database) or when a database file is attached to an existing database connection using the SQL ATTACH syntax. However if the shared-cache mode feature is enabled, then the database file may be accessed through an existing database connection. For more information on shared-cache mode, refer to Reference. The various IO operations required to open a new connection are detailed in section open_new_connection of this document.
Similarly, a database connection is usually closed when the user closes a database handle that is open on a real database file or has had one or more real database files attached to it using the ATTACH mechanism, or when a real database file is detached from a database connection using the DETACH syntax. Again, the exception is if shared-cache mode is enabled. In this case, a database connection is not closed until its number of users reaches zero. The IO related steps required to close a database connection are described in section closing_database_connection.
After sections 4 and 5 are finished, come back here and see if we can add a list of state items associated with each database connection to make things easier to understand. i.e each database connection has a file handle, a set of entries in the page cache, an expected page size etc.
Opening a New Connection
This section describes the VFS operations that take place when a new database connection is created.
Opening a new database connection is a two-step process:
- A file-handle is opened on the database file.
- If step 1 was successful, an attempt is made to read the database file header from the database file using the new file-handle.
In step 2 of the procedure above, the database file is not locked before it is read from. This is the only exception to the locking rules described in section reading_data.
The reason for attempting to read the database file header is to determine the page-size used by the database file. Because it is not possible to be certain as to the page-size without holding at least a shared lock on the database file (because some other database connection might have changed it since the database file header was read), the value read from the database file header is known as the expected page size.
When a new database connection is required, SQLite shall attempt to open a file-handle on the database file. If the attempt fails, then no new database connection is created and an error returned.
When a new database connection is required, after opening the new file-handle, SQLite shall attempt to read the first 100 bytes of the database file. If the attempt fails for any other reason than that the opened file is less than 100 bytes in size, then the file-handle is closed, no new database connection is created and an error returned instead.
If the database file header is successfully read from a newly opened database file, the connections expected page-size shall be set to the value stored in the page-size field of the database header.
If the database file header cannot be read from a newly opened database file (because the file is less than 100 bytes in size), the connections expected page-size shall be set to the compile time value of the SQLITE_DEFAULT_PAGESIZE option.
Closing a Connection
This section describes the VFS operations that take place when an existing database connection is closed (destroyed).
Closing a database connection is a simple matter. The open VFS file-handle is closed and in-memory page cache related resources are released.
When a database connection is closed, SQLite shall close the associated file handle at the VFS level.
When a database connection is closed, all associated page cache entries shall be discarded.
The Page Cache
The contents of an SQLite database file are formatted as a set of fixed size pages. See ff_sqlitert_requirements for a complete description of the format used. The page size used for a particular database is stored as part of the database file header at a well-known offset within the first 100 bytes of the file. Almost all read and write operations performed by SQLite on database files are done on blocks of data page-size bytes in size.
All SQLite database connections running within a single process share a single page cache. The page cache caches data read from database files in main-memory on a per-page basis. When SQLite requires data from a database file to satisfy a database query, it checks the page cache for usable cached versions of the required database pages before loading it from the database file. If no usable cache entry can be found and the database page data is loaded from the database file, it is cached in the page cache in case the same data is needed again later. Because reading from the database file is assumed to be an order of magnitude faster than reading from main-memory, caching database page content in the page cache to minimize the number of read operations performed on the database file is a significant performance enhancement.
The page cache is also used to buffer database write operations. When SQLite is required to modify one of more of the database pages that make up a database file, it first modifies the cached version of the page in the page cache. At that point the page is considered a "dirty" page. At some point later on, the new content of the "dirty" page is copied from the page cache into the database file via the VFS interface. Buffering writes in the page cache can reduce the number of write operations required on the database file (in cases where the same page is updated twice) and allows optimizations based on the assumptions outlined in section fs_performance.
Database read and write operations, and the way in which they interact with and use the page cache, are described in detail in sections reading_data and writing_data of this document, respectively.
At any one time, the page cache contains zero or more page cache entries, each of which has the following data associated with it:
A reference to the associated database connection. Each entry in the page cache is associated with a single database connection; the database connection that created the entry. A page cache entry is only ever used by the database connection that created it. Page cache entries are not shared between database connections.
The page number of the cached page. Pages are sequentially numbered within a database file starting from page 1 (page 1 begins at byte offset 0). Refer to ff_sqlitert_requirements for details.
The cached data; a blob of data page-size bytes in size.
The first two elements in the list above, the associated database connection and the page number, uniquely identify the page cache entry. At no time may the page cache contain two entries for which both the database connection and page number are identical. Or, put another way, a single database connection never caches more than one copy of a database page within the page cache.
At any one time, each page cache entry may be said to be a clean page, a non-writable dirty page or a writable dirty page, according to the following definitions:
-
A clean page is one for which the cached data currently matches the contents of the corresponding page of the database file. The page has not been modified since it was loaded from the file.
-
A dirty page is a page cache entry for which the cached data has been modified since it was loaded from the database file, and so no longer matches the current contents of the corresponding database file page. A dirty page is one that is currently buffering a modification made to the database file as part of a write transaction.
-
Within this document, the term non-writable dirty page is used specifically to refer to a page cache entry with modified content for which it is not yet safe to update the database file with. It is not safe to update a database file with a buffered write if a power or system failure that occurs during or soon after the update may cause the database to become corrupt following system recovery, according to the assumptions made in section fs_assumption_details.
-
A dirty page for which it would be safe to update the corresponding database file page with the modified contents of without risking database corruption is known as a writable dirty page.
The exact logic used to determine if a page cache entry with modified content is a dirty page or writable page is presented in section page_cache_algorithms.
Because main-memory is a limited resource, the page cache cannot be allowed to grow indefinitely. As a result, unless all database files opened by database connections within the process are quite small, sometimes data must be discarded from the page cache. In practice this means page cache entries must be purged to make room for new ones. If a page cache entry being removed from the page cache to free main-memory is a dirty page, then its contents must be saved into the database file before it can be discarded without data loss. The following two sub-sections describe the algorithms used by the page cache to determine exactly when existing page cache entries are purged (discarded).
Page Cache Configuration
Describe the parameters set to configure the page cache limits.
Page Cache Algorithms
Requirements describing the way in which the configuration parameters are used. About LRU etc.
Reading Data
In order to return data from the database to the user, for example as the results of a SELECT query, SQLite must at some point read data from the database file. Usually, data is read from the database file in aligned blocks of page-size bytes. The exception is when the database file header fields are being inspected, before the page-size used by the database can be known.
With two exceptions, a database connection must have an open transaction (either a read-only transaction or a read/write transaction) on the database before data may be read from the database file.
The two exceptions are:
- When an attempt is made to read the 100 byte database file header immediately after opening the database connection (see section open_new_connection). When this occurs no lock is held on the database file.
- Data read while in the process of opening a read-only transaction (see section open_read_only_trans). These read operations occur after a shared lock is held on the database file.
Once a transaction has been opened, reading data from a database connection is a simple operation. Using the xRead() method of the file-handle open on the database file, the required database file pages are read one at a time. SQLite never reads partial pages and always uses a single call to xRead() for each required page.
After reading the data for a database page, SQLite stores the raw page of data in the page cache. Each time a page of data is required by the upper layers, the page cache is queried to see if it contains a copy of the required page stored by the current database connection. If such an entry can be found, then the required data is read from the page cache instead of the database file. Only a connection with an open transaction transaction (either a read-only transaction or a read/write transaction) on the database may read data from the page cache. In this sense reading from the page cache is no different to reading from the database file.
Refer to section page_cache_algorithms for a description of exactly how and for how long page data is stored in the page cache.
Except for the read operation required by H35070 and those reads made as part of opening a read-only transaction, SQLite shall ensure that a database connection has an open read-only or read/write transaction when any data is read from the database file.
Aside from those read operations described by H35070 and H21XXX, SQLite shall read data from the database file in aligned blocks of page-size bytes, where page-size is the database page size used by the database file.
SQLite shall ensure that a database connection has an open read-only or read/write transaction before using data stored in the page cache to satisfy user queries.
Opening a Read-Only Transaction
Before data may be read from a database file or queried from the page cache, a read-only transaction must be successfully opened by the associated database connection (this is true even if the connection will eventually write to the database, as a read/write transaction may only be opened by upgrading from a read-only transaction). This section describes the procedure for opening a read-only transaction.
The key element of a read-only transaction is that the file-handle open on the database file obtains and holds a shared-lock on the database file. Because a connection requires an exclusive-lock before it may actually modify the contents of the database file, and by definition while one connection is holding a shared-lock no other connection may hold an exclusive-lock, holding a shared-lock guarantees that no other process may modify the database file while the read-only transaction remains open. This ensures that read-only transactions are sufficiently isolated from the transactions of other database users (see section overview).
Obtaining the shared lock itself on the database file is quite simple, SQLite just calls the xLock() method of the database file handle. Some of the other processes that take place as part of opening the read-only transaction are quite complex. The steps that SQLite is required to take to open a read-only transaction, in the order in which they must occur, is as follows:
- A shared-lock is obtained on the database file.
- The connection checks if a hot journal file exists in the file-system. If one does, then it is rolled back before continuing.
- The connection checks if the data in the page cache may still be trusted. If not, all page cache data is discarded.
- If the file-size is not zero bytes and the page cache does not contain valid data for the first page of the database, then the data for the first page must be read from the database.
Of course, an error may occur while attempting any of the 4 steps enumerated above. If this happens, then the shared-lock is released (if it was obtained) and an error returned to the user. Step 2 of the procedure above is described in more detail in section hot_journal_detection. Section cache_validation describes the process identified by step 3 above. Further detail on step 4 may be found in section read_page_one.
When required to open a read-only transaction using a database connection, SQLite shall first attempt to obtain a shared-lock on the file-handle open on the database file.
If, while opening a read-only transaction, SQLite fails to obtain the shared-lock on the database file, then the process is abandoned, no transaction is opened and an error returned to the user.
The most common reason an attempt to obtain a shared-lock may fail is that some other connection is holding an exclusive or pending lock. However it may also fail because some other error (e.g. an IO or comms related error) occurs within the call to the xLock() method.
While opening a read-only transaction, after successfully obtaining a shared lock on the database file, SQLite shall attempt to detect and roll back a hot journal file associated with the same database file.
If, while opening a read-only transaction, SQLite encounters an error while attempting to detect or roll back a hot journal file, then the shared-lock on the database file is released, no transaction is opened and an error returned to the user.
Section hot_journal_detection contains a description of and requirements governing the detection of a hot-journal file referred to in the above requirements.
Assuming no errors have occurred, then after attempting to detect and roll back a hot journal file, if the page cache contains any entries associated with the current database connection, then SQLite shall validate the contents of the page cache by testing the file change counter. This procedure is known as cache validation.
The cache validation process is described in detail in section cache_validation
If the cache validate procedure prescribed by H35040 is required and does not prove that the page cache entries associated with the current database connection are valid, then SQLite shall discard all entries associated with the current database connection from the page cache.
The numbered list above notes that the data for the first page of the database file, if it exists and is not already loaded into the page cache, must be read from the database file before the read-only transaction may be considered opened. This is handled by requirement H35240.
Hot Journal Detection
This section describes the procedure that SQLite uses to detect a hot journal file. If a hot journal file is detected, this indicates that at some point the process of writing a transaction to the database was interrupted and a recovery operation (hot journal rollback) needs to take place. This section does not describe the process of hot journal rollback (see section hot_journal_rollback) or the processes by which a hot journal file may be created (see section writing_data).
The procedure used to detect a hot-journal file is quite complex. The following steps take place:
- Using the VFS xAccess() method, SQLite queries the file-system to see if the journal file associated with the database exists. If it does not, then there is no hot-journal file.
- By invoking the xCheckReservedLock() method of the file-handle opened on the database file, SQLite checks if some other connection holds a reserved lock or greater. If some other connection does hold a reserved lock, this indicates that the other connection is midway through a read/write transaction (see section writing_data). In this case the journal file is not a hot-journal and must not be rolled back.
- Using the xFileSize() method of the file-handle opened on the database file, SQLite checks if the database file is 0 bytes in size. If it is, the journal file is not considered to be a hot journal file. Instead of rolling back the journal file, in this case it is deleted from the file-system by calling the VFS xDelete() method. Technically, there is a race condition here. This step should be moved to after the exclusive lock is held.
- An attempt is made to upgrade to an exclusive lock on the database file. If the attempt fails, then all locks, including the recently obtained shared lock are dropped. The attempt to open a read-only transaction has failed. This occurs when some other connection is also attempting to open a read-only transaction and the attempt to gain the exclusive lock fails because the other connection is also holding a shared lock. It is left to the other connection to roll back the hot journal. It is important that the file-handle lock is upgraded directly from shared to exclusive in this case, instead of first upgrading to reserved or pending locks as is required when obtaining an exclusive lock to write to the database file (section writing_data). If SQLite were to first upgrade to a reserved or pending lock in this scenario, then a second process also trying to open a read-transaction on the database file might detect the reserved lock in step 2 of this process, conclude that there was no hot journal, and commence reading data from the database file.
- The xAccess() method is invoked again to detect if the journal file is still in the file system. If it is, then it is a hot-journal file and SQLite tries to roll it back (see section rollback).
Master journal file pointers?
The following requirements describe step 1 of the above procedure in more detail.
When required to attempt to detect a hot-journal file, SQLite shall first use the xAccess() method of the VFS layer to check if a journal file exists in the file-system.
If the call to xAccess() required by H35140 fails (due to an IO error or similar), then SQLite shall abandon the attempt to open a read-only transaction, relinquish the shared lock held on the database file and return an error to the user.
When required to attempt to detect a hot-journal file, if the call to xAccess() required by H35140 indicates that a journal file does not exist, then SQLite shall conclude that there is no hot-journal file in the file system and therefore that no hot journal rollback is required.
The following requirements describe step 2 of the above procedure in more detail.
When required to attempt to detect a hot-journal file, if the call to xAccess() required by H35140 indicates that a journal file is present, then the xCheckReservedLock() method of the database file file-handle is invoked to determine whether or not some other process is holding a reserved or greater lock on the database file.
If the call to xCheckReservedLock() required by H35160 fails (due to an IO or other internal VFS error), then SQLite shall abandon the attempt to open a read-only transaction, relinquish the shared lock held on the database file and return an error to the user.
If the call to xCheckReservedLock() required by H35160 indicates that some other database connection is holding a reserved or greater lock on the database file, then SQLite shall conclude that there is no hot journal file. In this case the attempt to detect a hot journal file is concluded.
The following requirements describe step 3 of the above procedure in more detail.
If while attempting to detect a hot-journal file the call to xCheckReservedLock() indicates that no process holds a reserved or greater lock on the database file, then SQLite shall open a file handle on the potentially hot journal file using the VFS xOpen() method.
If the call to xOpen() required by H35440 fails (due to an IO or other internal VFS error), then SQLite shall abandon the attempt to open a read-only transaction, relinquish the shared lock held on the database file and return an error to the user.
After successfully opening a file-handle on a potentially hot journal file, SQLite shall query the file for its size in bytes using the xFileSize() method of the open file handle.
If the call to xFileSize() required by H35450 fails (due to an IO or other internal VFS error), then SQLite shall abandon the attempt to open a read-only transaction, relinquish the shared lock held on the database file, close the file handle opened on the journal file and return an error to the user.
If the size of a potentially hot journal file is revealed to be zero bytes by a query required by H35450, then SQLite shall close the file handle opened on the journal file and delete the journal file using a call to the VFS xDelete() method. In this case SQLite shall conclude that there is no hot journal file.
If the call to xDelete() required by H35450 fails (due to an IO or other internal VFS error), then SQLite shall abandon the attempt to open a read-only transaction, relinquish the shared lock held on the database file and return an error to the user.
The following requirements describe step 4 of the above procedure in more detail.
If the size of a potentially hot journal file is revealed to be greater than zero bytes by a query required by H35450, then SQLite shall attempt to upgrade the shared lock held by the database connection on the database file directly to an exclusive lock.
If an attempt to upgrade to an exclusive lock prescribed by H35470 fails for any reason, then SQLite shall release all locks held by the database connection and close the file handle opened on the journal file. The attempt to open a read-only transaction shall be deemed to have failed and an error returned to the user.
Finally, the following requirements describe step 5 of the above procedure in more detail.
If, as part of the hot journal file detection process, the attempt to upgrade to an exclusive lock mandated by H35470 is successful, then SQLite shall query the file-system using the xAccess() method of the VFS implementation to test whether or not the journal file is still present in the file-system.
If the call to xAccess() required by H35490 fails (due to an IO or other internal VFS error), then SQLite shall abandon the attempt to open a read-only transaction, relinquish the lock held on the database file, close the file handle opened on the journal file and return an error to the user.
If the call to xAccess() required by H35490 reveals that the journal file is no longer present in the file system, then SQLite shall abandon the attempt to open a read-only transaction, relinquish the lock held on the database file, close the file handle opened on the journal file and return an SQLITE_BUSY error to the user.
If the xAccess() query required by H35490 reveals that the journal file is still present in the file system, then SQLite shall conclude that the journal file is a hot journal file that needs to be rolled back. SQLite shall immediately begin hot journal rollback.
Cache Validation
When a database connection opens a read transaction, the page cache may already contain data associated with the database connection. However, if another process has modified the database file since the cached pages were loaded it is possible that the cached data is invalid.
SQLite determines whether or not the page cache entries belonging to the database connection are valid or not using the file change counter, a field in the database file header. The file change counter is a 4-byte big-endian integer field stored starting at byte offset 24 of the database file header. Before the conclusion of a read/write transaction that modifies the contents of the database file in any way (see section writing_data), the value stored in the file change counter is incremented. When a database connection unlocks the database file, it stores the current value of the file change counter. Later, while opening a new read-only transaction, SQLite checks the value of the file change counter stored in the database file. If the value has not changed since the database file was unlocked, then the page cache entries can be trusted. If the value has changed, then the page cache entries cannot be trusted and all entries associated with the current database connection are discarded.
When a file-handle open on a database file is unlocked, if the page cache contains one or more entries belonging to the associated database connection, SQLite shall store the value of the file change counter internally.
When required to perform cache validation as part of opening a read transaction, SQLite shall read a 16 byte block starting at byte offset 24 of the database file using the xRead() method of the database connections file handle.
Why a 16 byte block? Why not 4? (something to do with encrypted databases).
While performing cache validation, after loading the 16 byte block as required by H35190, SQLite shall compare the 32-bit big-endian integer stored in the first 4 bytes of the block to the most recently stored value of the file change counter (see H35180). If the values are not the same, then SQLite shall conclude that the contents of the cache are invalid.
Requirement H35050 (section open_read_only_trans) specifies the action SQLite is required to take upon determining that the cache contents are invalid.
Page 1 and the Expected Page Size
As the last step in opening a read transaction on a database file that is more than 0 bytes in size, SQLite is required to load data for page 1 of the database into the page cache, if it is not already there. This is slightly more complicated than it seems, as the database page-size is no known at this point.
Even though the database page-size cannot be known for sure, SQLite is usually able to guess correctly by assuming it to be equal to the connections expected page size. The expected page size is the value of the page-size field read from the database file header while opening the database connection (see section open_new_connection), or the page-size of the database file when the most read transaction was concluded.
During the conclusion of a read transaction, before unlocking the database file, SQLite shall set the connections expected page size to the current database page-size.
As part of opening a new read transaction, immediately after performing cache validation, if there is no data for database page 1 in the page cache, SQLite shall read N bytes from the start of the database file using the xRead() method of the connections file handle, where N is the connections current expected page size value.
If page 1 data is read as required by H35230, then the value of the page-size field that appears in the database file header that consumes the first 100 bytes of the read block is not the same as the connections current expected page size, then the expected page size is set to this value, the database file is unlocked and the entire procedure to open a read transaction is repeated.
If page 1 data is read as required by H35230, then the value of the page-size field that appears in the database file header that consumes the first 100 bytes of the read block is the same as the connections current expected page size, then the block of data read is stored in the page cache as page 1.
Reading Database Data
Add something about checking the page-cache first etc.
Ending a Read-only Transaction
To end a read-only transaction, SQLite simply relinquishes the shared lock on the file-handle open on the database file. No other action is required.
When required to end a read-only transaction, SQLite shall relinquish the shared lock held on the database file by calling the xUnlock() method of the file-handle.
See also requirements H35180 and H35210 above.
Writing Data
Using DDL or DML SQL statements, SQLite users may modify the contents and size of a database file. Exactly how changes to the logical database are translated to modifications to the database file is described in ff_sqlitert_requirements. From the point of view of the sub-systems described in this document, each DDL or DML statement executed results in the contents of zero or more database file pages being overwritten with new data. A DDL or DML statement may also append or truncate one or more pages to or from the end of the database file. One or more DDL and/or DML statements are grouped together to make up a single write transaction. A write transaction is required to have the special properties described in section overview; a write transaction must be isolated, durable and atomic.
SQLite accomplishes these goals using the following techniques:
To ensure that write transactions are isolated, before beginning to modify the contents of the database file to reflect the results of a write transaction, SQLite obtains an exclusive lock on the database file. The lock is not relinquished until the write transaction is concluded. Because reading from the database file requires a shared lock (see section reading_data) and holding an exclusive lock guarantees that no other database connection is holding or can obtain a shared lock, this ensures that no other connection may read data from the database file at a point when a write transaction has been partially applied.
Ensuring that write transactions are atomic is the most complex task required of the system. In this case, atomic means that even if a system failure occurs, an attempt to commit a write transaction to the database file either results in all changes that are a part of the transaction being successfully applied to the database file, or none of the changes are successfully applied. There is no chance that a subset of the changes only are applied. Hence from the point of view of an external observer, the write transaction appears to be an atomic event.
Of course, it is usually not possible to atomically apply all the changes required by a write transaction to a database file within the file-system. For example, if a write transaction requires ten pages of a database file to be modified, and a power outage causes a system failure after sqlite has modified only five pages, then the database file will almost certainly be in an inconsistent state following system recovery.
SQLite solves this problem by using a journal file. In almost all cases, before the database file is modified in any way, SQLite stores sufficient information in the journal file to allow the original the database file to be reconstructed if a system failure occurs while the database file is being updated to reflect the modifications made by the write transaction. Each time SQLite opens a database file, it checks if such a system failure has occurred and, if so, reconstructs the database file based on the contents of the journal file. The procedure used to detect whether or not this process, coined hot journal rollback, is required is described in section hot_journal_detection. Hot journal rollback itself is described in section hot_journal_rollback.
The same technique ensures that an SQLite database file cannot be corrupted by a system failure that occurs at an inopportune moment. If a system failure does occur before SQLite has had a chance to execute sufficient sync file operations to ensure that the changes that make up a write transaction have made it safely to persistent storage, then the journal file will be used to restore the database to a known good state following system recovery.
So that write transactions are durable in the face of a system failure, SQLite executes a sync file operation on the database file before concluding the write transaction
The page cache is used to buffer modifications to the database file image before they are written to the database file. When the contents of a page is required to be modified as the results of an operation within a write transaction, the modified copy is stored in the page cache. Similarly, if new pages are appended to the end of a database file, they are added to the page cache instead of being immediately written to the database file within the file-system.
Ideally, all changes for an entire write transaction are buffered in the page cache until the end of the transaction. When the user commits the transaction, all changes are applied to the database file in the most efficient way possible, taking into account the assumptions enumerated in section fs_performance. Unfortunately, since main-memory is a limited resource, this is not always possible for large transactions. In this case changes are buffered in the page cache until some internal condition or limit is reached, then written out to the database file in order to free resources as they are required. Section page_cache_algorithms describes the circumstances under which changes are flushed through to the database file mid-transaction to free page cache resources.
Even if an application or system failure does not occur while a write transaction is in progress, a rollback operation to restore the database file and page cache to the state that it was in before the transaction started may be required. This may occur if the user explicitly requests transaction rollback (by issuing a "ROLLBACK" command), or automatically, as a result of encountering an SQL constraint (see sql_sqlitert_requirements). For this reason, the original page content is stored in the journal file before the page is even modified within the page cache.
Introduce the following sub-sections.
Journal File Format
This section describes the format used by an SQLite journal file.
A journal file consists of one or more journal headers, zero or more journal records and optionally a master journal pointer. Each journal file always begins with a journal header, followed by zero or more journal records. Following this may be a second journal header followed by a second set of zero or more journal records and so on. There is no limit to the number of journal headers a journal file may contain. Following the journal headers and their accompanying sets of journal records may be the optional master journal pointer. Or, the file may simply end following the final journal record.
This section only describes the format of the journal file and the various objects that make it up. But because a journal file may be read by an SQLite process following recovery from a system failure (hot journal rollback, see section hot_journal_rollback) it is also important to describe the way the file is created and populated within the file-system using a combination of write file, sync file and truncate file operations. These are described in section write_transactions.
Journal Header Format
A journal header is sector-size bytes in size, where sector-size is the value returned by the xSectorSize method of the file handle opened on the database file. Only the first 28 bytes of the journal header are used, the remainder may contain garbage data. The first 28 bytes of each journal header consists of an eight byte block set to a well-known value, followed by five big-endian 32-bit unsigned integer fields.
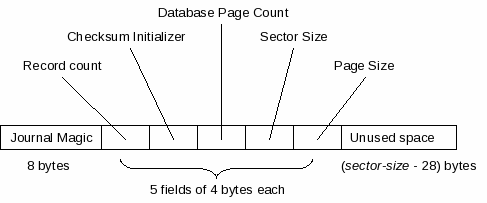
Figure - Journal Header Format
Figure figure_journal_header graphically depicts the layout of a journal header. The individual fields are described in the following table. The offsets in the 'byte offset' column of the table are relative to the start of the journal header.
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 8 | The journal magic field always contains a
well-known 8-byte string value used to identify SQLite
journal files. The well-known sequence of byte values
is:
0xd9 0xd5 0x05 0xf9 0x20 0xa1 0x63 0xd7 |
| 8 | 4 | This field, the record count, is set to the number of journal records that follow this journal header in the journal file. |
| 12 | 4 | The checksum initializer field is set to a pseudo-random value. It is used as part of the algorithm to calculate the checksum for all journal records that follow this journal header. |
| 16 | 4 | This field, the database page count, is set to the number of pages that the database file contained before any modifications associated with write transaction are applied. |
| 20 | 4 | This field, the sector size, is set to the sector size of the device on which the journal file was created, in bytes. This value is required when reading the journal file to determine the size of each journal header. |
| 24 | 4 | The page size field contains the database page size used by the corresponding database file when the journal file was created, in bytes. |
All journal headers are positioned in the file so that they start at a sector size aligned offset. To achieve this, unused space may be left between the start of the second and subsequent journal headers and the end of the journal records associated with the previous header.
Journal Record Format
Each journal record contains the original data for a database page modified by the write transaction. If a rollback is required, then this data may be used to restore the contents of the database page to the state it was in before the write transaction was started.

Figure - Journal Record Format
A journal record, depicted graphically by figure figure_journal_record, contains three fields, as described in the following table. Byte offsets are relative to the start of the journal record.
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 4 | The page number of the database page associated with this journal record, stored as a 4 byte big-endian unsigned integer. |
| 4 | page-size | This field contains the original data for the page, exactly as it appeared in the database file before the write transaction began. |
| 4 + page-size | 4 | This field contains a checksum value, calculated based on the contents of the journaled database page data (the previous field) and the values stored in the checksum initializer field of the preceding journal header. |
The set of journal records that follow a journal header in a journal file are packed tightly together. There are no alignment requirements for journal records as there are for journal headers.
Master Journal Pointer
To support atomic transactions that modify more than one database file, SQLite sometimes includes a master journal pointer record in a journal file. Multiple file transactions are described in section multifile_transactions. A master journal pointer contains the name of a master journal-file along with a check-sum and some well known values that allow the master journal pointer to be recognized as such when the journal file is read during a rollback operation (section rollback).
As is the case for a journal header, the start of a master journal pointer is always positioned at a sector size aligned offset. If the journal record or journal header that appears immediately before the master journal pointer does not end at an aligned offset, then unused space is left between the end of the journal record or journal header and the start of the master journal pointer.
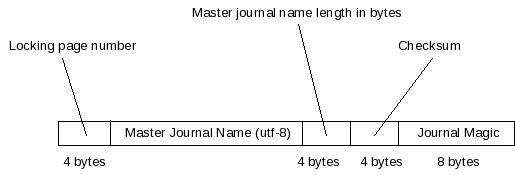
Figure - Master Journal Pointer Format
A master journal pointer, depicted graphically by figure figure_master_journal_ptr, contains five fields, as described in the following table. Byte offsets are relative to the start of the master journal pointer.
| Byte offset | Size in bytes | Description |
|---|---|---|
| 0 | 4 | This field, the locking page number, is always
set to the page number of the database locking page
stored as a 4-byte big-endian integer. The locking page
is the page that begins at byte offset 2 |
| 4 | name-length | The master journal name field contains the name of the master journal file, encoded as a utf-8 string. There is no nul-terminator appended to the string. |
| 4 + name-length | 4 | The name-length field contains the length of the previous field in bytes, formatted as a 4-byte big-endian unsigned integer. |
| 8 + name-length | 4 | The checksum field contains a checksum value stored as a 4-byte big-endian signed integer. The checksum value is calculated as the sum of the bytes that make up the master journal name field, interpreting each byte as an 8-bit signed integer. |
| 12 + name-length | 8 |
Finally, the journal magic field always contains a
well-known 8-byte string value; the same value stored in the
first 8 bytes of a journal header. The well-known
sequence of bytes is:
0xd9 0xd5 0x05 0xf9 0x20 0xa1 0x63 0xd7 |
Write Transactions
This section describes the progression of an SQLite write transaction. From the point of view of the systems described in this document, most write transactions consist of three steps:
The write transaction is opened. This process is described in section opening_a_write_transaction.
The end-user executes DML or DDL SQL statements that require the structure of the database file of the database file to be modified. These modifications may be any combination of operations to
- modify the content of an existing database page,
- append a new database page to the database file image, or
- truncate (discard) a database page from the end of the database file.
The write transaction is concluded and the changes made permanently committed to the database. The process required to commit a transaction is described in section committing_a_transaction.
As an alternative to step 3 above, the transaction may be rolled back. Transaction rollback is described in section rollback. Finally, it is also important to remember that a write transaction may be interrupted by a system failure at any point. In this case, the contents of the file-system (the database file and journal file) must be left in such a state so as to enable the database file to be restored to the state it was in before the interrupted write transaction was started. This is known as hot journal rollback, and is described in section hot_journal_rollback. Section fs_assumption_details describes the assumptions made regarding the effects of a system failure on the file-system contents following recovery.
Beginning a Write Transaction
Before any database pages may be modified within the page cache, the database connection must open a write transaction. Opening a write transaction requires that the database connection obtains a reserved lock (or greater) on the database file. Because a obtaining a reserved lock on a database file guarantees that no other database connection may hold or obtain a reserved lock or greater, it follows that no other database connection may have an open write transaction.
A reserved lock on the database file may be thought of as an exclusive lock on the journal file. No database connection may read from or write to a journal file without a reserved or greater lock on the corresponding database file.
Before opening a write transaction, a database connection must have an open read transaction, opened via the procedure described in section open_read_only_trans. This ensures that there is no hot-journal file that needs to be rolled back and that any data stored in the page cache can be trusted.
Once a read transaction has been opened, upgrading to a write transaction is a two step process, as follows:
- A reserved lock is obtained on the database file.
- The journal file is opened and created if necessary (using the VFS xOpen method), and a journal file header written to the start of it using a single call to the file handles xWrite method.
Requirements describing step 1 of the above procedure in detail:
When required to open a write transaction on the database, SQLite shall first open a read transaction, if the database connection in question has not already opened one.
When required to open a write transaction on the database, after ensuring a read transaction has already been opened, SQLite shall obtain a reserved lock on the database file by calling the xLock method of the file-handle open on the database file.
If an attempt to acquire a reserved lock prescribed by requirement H35360 fails, then SQLite shall deem the attempt to open a write transaction to have failed and return an error to the user.
Requirements describing step 2 of the above procedure in detail:
When required to open a write transaction on the database, after obtaining a reserved lock on the database file, SQLite shall open a read/write file-handle on the corresponding journal file.
When required to open a write transaction on the database, after opening a file-handle on the journal file, SQLite shall append a journal header to the (currently empty) journal file.
Writing a Journal Header
Requirements describing how a journal header is appended to a journal file:
When required to append a journal header to the journal file, SQLite shall do so by writing a block of sector-size bytes using a single call to the xWrite method of the file-handle open on the journal file. The block of data written shall begin at the smallest sector-size aligned offset at or following the current end of the journal file.
The first 8 bytes of the journal header required to be written by H35680 shall contain the following values, in order from byte offset 0 to 7: 0xd9, 0xd5, 0x05, 0xf9, 0x20, 0xa1, 0x63 and 0xd7.
Bytes 8-11 of the journal header required to be written by H35680 shall contain 0x00.
Bytes 12-15 of the journal header required to be written by H35680 shall contain the number of pages that the database file contained when the current write-transaction was started, formatted as a 4-byte big-endian unsigned integer.
Bytes 16-19 of the journal header required to be written by H35680 shall contain pseudo-randomly generated values.
Bytes 20-23 of the journal header required to be written by H35680 shall contain the sector size used by the VFS layer, formatted as a 4-byte big-endian unsigned integer.
Bytes 24-27 of the journal header required to be written by H35680 shall contain the page size used by the database at the start of the write transaction, formatted as a 4-byte big-endian unsigned integer.
Modifying, Adding or Truncating a Database Page
When the end-user executes a DML or DDL SQL statement to modify the database schema or content, SQLite is required to update the database file image to reflect the new database state. This involves modifying the content of, appending or truncating one of more database file pages. Instead of modifying the database file directly using the VFS interface, changes are first buffered within the page cache.
Before modifying a database page within the page cache that may need to be restored by a rollback operation, the page must be journalled. Journalling a page is the process of copying that pages original data into the journal file so that it can be recovered if the write transaction is rolled back. The process of journalling a page is described in section journalling_a_page.
When required to modify the contents of an existing database page that existed and was not a free-list leaf page when the write transaction was opened, SQLite shall journal the page if it has not already been journalled within the current write transaction.
When required to modify the contents of an existing database page, SQLite shall update the cached version of the database page content stored as part of the page cache entry associated with the page.
When a new database page is appended to a database file, there is no requirement to add a record to the journal file. If a rollback is required the database file will simply be truncated back to its original size based on the value stored at byte offset 12 of the journal file.
When required to append a new database page to the database file, SQLite shall create a new page cache entry corresponding to the new page and insert it into the page cache. The dirty flag of the new page cache entry shall be set.
If required to truncate a database page from the end of the database file, the associated page cache entry is discarded. The adjusted size of the database file is stored internally. The database file is not actually truncated until the current write transaction is committed (see section committing_a_transaction).
When required to truncate (remove) a database page that existed and was not a free-list leaf page when the write transaction was opened from the end of a database file, SQLite shall journal the page if it has not already been journalled within the current write transaction.
When required to truncate a database page from the end of the database file, SQLite shall discard the associated page cache entry from the page cache.
Journalling a Database Page
A page is journalled by adding a journal record to the journal file. The format of a journal record is described in section journal_record_format.
When required to journal a database page, SQLite shall first append the page number of the page being journalled to the journal file, formatted as a 4-byte big-endian unsigned integer, using a single call to the xWrite method of the file-handle opened on the journal file.
When required to journal a database page, if the attempt to append the page number to the journal file is successful, then the current page data (page-size bytes) shall be appended to the journal file, using a single call to the xWrite method of the file-handle opened on the journal file.
When required to journal a database page, if the attempt to append the current page data to the journal file is successful, then SQLite shall append a 4-byte big-endian integer checksum value to the to the journal file, using a single call to the xWrite method of the file-handle opened on the journal file.
The checksum value written to the journal file immediately after the page data (requirement H35290), is a function of both the page data and the checksum initializer field stored in the journal header (see section journal_header_format). Specifically, it is the sum of the checksum initializer and the value of every 200th byte of page data interpreted as an 8-bit unsigned integer, starting with the (page-size % 200)'th byte of page data. For example, if the page-size is 1024 bytes, then a checksum is calculated by adding the values of the bytes at offsets 23, 223, 423, 623, 823 and 1023 (the last byte of the page) together with the value of the checksum initializer.
The checksum value written to the journal file by the write required by H35290 shall be equal to the sum of the checksum initializer field stored in the journal header (H35700) and every 200th byte of the page data, beginning with the (page-size % 200)th byte.
The '%' character is used in requirement H35300 to represent the modulo operator, just as it is in programming languages such as C, Java and Javascript.
Syncing the Journal File
Even after the original data of a database page has been written into the journal file using calls to the journal file file-handle xWrite method (section journalling_a_page), it is still not safe to write to the page within the database file. This is because in the event of a system failure the data written to the journal file may still be corrupted (see section fs_characteristics). Before the page can be updated within the database itself, the following procedure takes place:
- The xSync method of the file-handle opened on the journal file is called. This operation ensures that all journal records in the journal file have been written to persistent storage, and that they will not become corrupted as a result of a subsequent system failure.
- The journal record count field (see section journal_header_format) of the most recently written journal header in the journal file is updated to contain the number of journal records added to the journal file since the header was written.
- The xSync method is called again, to ensure that the update to the journal record count has been committed to persistent storage.
If all three of the steps enumerated above are executed successfully, then it is safe to modify the content of the journalled database pages within the database file itself. The combination of the three steps above is referred to as syncing the journal file.
When required to sync the journal file, SQLite shall invoke the xSync method of the file handle open on the journal file.
When required to sync the journal file, after invoking the xSync method as required by H35750, SQLite shall update the record count of the journal header most recently written to the journal file. The 4-byte field shall be updated to contain the number of journal records that have been written to the journal file since the journal header was written, formatted as a 4-byte big-endian unsigned integer.
When required to sync the journal file, after updating the record count field of a journal header as required by H35760, SQLite shall invoke the xSync method of the file handle open on the journal file.
Upgrading to an Exclusive Lock
Before the content of a page modified within the page cache may be written to the database file, an exclusive lock must be held on the database file. The purpose of this lock is to prevent another connection from reading from the database file while the first connection is midway through writing to it. Whether the reason for writing to the database file is because a transaction is being committed, or to free up space within the page cache, upgrading to an exclusive lock always occurs immediately after syncing the journal file.
When required to upgrade to an exclusive lock as part of a write transaction, SQLite shall first attempt to obtain a pending lock on the database file if one is not already held by invoking the xLock method of the file handle opened on the database file.
When required to upgrade to an exclusive lock as part of a write transaction, after successfully obtaining a pending lock SQLite shall attempt to obtain an exclusive lock by invoking the xLock method of the file handle opened on the database file.
What happens if the exclusive lock cannot be obtained? It is not possible for the attempt to upgrade from a reserved to a pending lock to fail.
Committing a Transaction
Committing a write transaction is the final step in updating the database file. Committing a transaction is a seven step process, summarized as follows:
The database file header change counter field is incremented. The change counter, described in ff_sqlitert_requirements, is used by the cache validation procedure described in section cache_validation.
The journal file is synced. The steps required to sync the journal file are described in section syncing_journal_file.
Upgrade to an exclusive lock on the database file, if an exclusive lock is not already held. Upgrading to an exclusive lock is described in section upgrading_to_exclusive_lock.
Copy the contents of all dirty pages stored in the page cache into the database file. The set of dirty pages are written to the database file in page number order in order to improve performance (see the assumptions in section fs_performance for details).
The database file is synced to ensure that all updates are stored safely on the persistent media.
The file-handle open on the journal file is closed and the journal file itself deleted. At this point the write transaction transaction has been irrevocably committed.
The database file is unlocked.
Expand on and explain the above a bit.
The following requirements describe the steps enumerated above in more detail.
When required to commit a write-transaction, SQLite shall modify page 1 to increment the value stored in the change counter field of the database file header.
The change counter is a 4-byte big-endian integer field stored at byte offset 24 of the database file. The modification to page 1 required by H35800 is made using the process described in section modifying_appending_truncating. If page 1 has not already been journalled as a part of the current write-transaction, then incrementing the change counter may require that page 1 be journalled. In all cases the page cache entry corresponding to page 1 becomes a dirty page as part of incrementing the change counter value.
When required to commit a write-transaction, after incrementing the change counter field, SQLite shall sync the journal file.
When required to commit a write-transaction, after syncing the journal file as required by H35810, if an exclusive lock on the database file is not already held, SQLite shall attempt to upgrade to an exclusive lock.
When required to commit a write-transaction, after syncing the journal file as required by H35810 and ensuring that an exclusive lock is held on the database file as required by H35830, SQLite shall copy the contents of all dirty page stored in the page cache into the database file using calls to the xWrite method of the database connection file handle. Each call to xWrite shall write the contents of a single dirty page (page-size bytes of data) to the database file. Dirty pages shall be written in order of page number, from lowest to highest.
When required to commit a write-transaction, after copying the contents of any dirty pages to the database file as required by H35830, SQLite shall sync the database file by invoking the xSync method of the database connection file handle.
When required to commit a write-transaction, after syncing the database file as required by H35840, SQLite shall close the file-handle opened on the journal file and delete the journal file from the file system via a call to the VFS xDelete method.
When required to commit a write-transaction, after deleting the journal file as required by H35850, SQLite shall relinquish all locks held on the database file by invoking the xUnlock method of the database connection file handle.
Is the shared lock held after committing a write transaction?
Purging a Dirty Page
Usually, no data is actually written to the database file until the user commits the active write transaction. The exception is if a single write transaction contains too many modifications to be stored in the page cache. In this case, some of the database file modifications stored in the page cache must be applied to the database file before the transaction is committed so that the associated page cache entries can be purged from the page cache to free memory. Exactly when this condition is reached and dirty pages must be purged is described in section page_cache_algorithms.
Before the contents of the page cache entry can be written into the database file, the page cache entry must meet the criteria for a writable dirty page, as defined in section page_cache_algorithms. If the dirty page selected by the algorithms in section page_cache_algorithms for purging, SQLite is required to sync the journal file. Immediately after the journal file is synced, all dirty pages associated with the database connection are classified as writable dirty pages.
When required to purge a non-writable dirty page from the page cache, SQLite shall sync the journal file before proceeding with the write operation required by H35670.
After syncing the journal file as required by H35640, SQLite shall append a new journal header to the journal file before proceeding with the write operation required by H35670.
Appending a new journal header to the journal file is described in section writing_journal_header.
Once the dirty page being purged is writable, it is simply written into the database file.
When required to purge a page cache entry that is a dirty page SQLite shall write the page data into the database file, using a single call to the xWrite method of the database connection file handle.
Multi-File Transactions
Statement Transactions
Rollback
Hot Journal Rollback
Transaction Rollback
Statement Rollback
References
| [1] | C API Requirements Document. |
| [2] | SQL Requirements Document. |
| [3] | File Format Requirements Document. |